Wenn sich Bot-Traffic plötzlich vertausendfacht
Heute Morgen gab es bei einem unserer Kunden immer wieder kurze Ausfälle. Keine komplette Störung, sondern eher so: alles läuft. Und dann plötzlich nicht mehr!
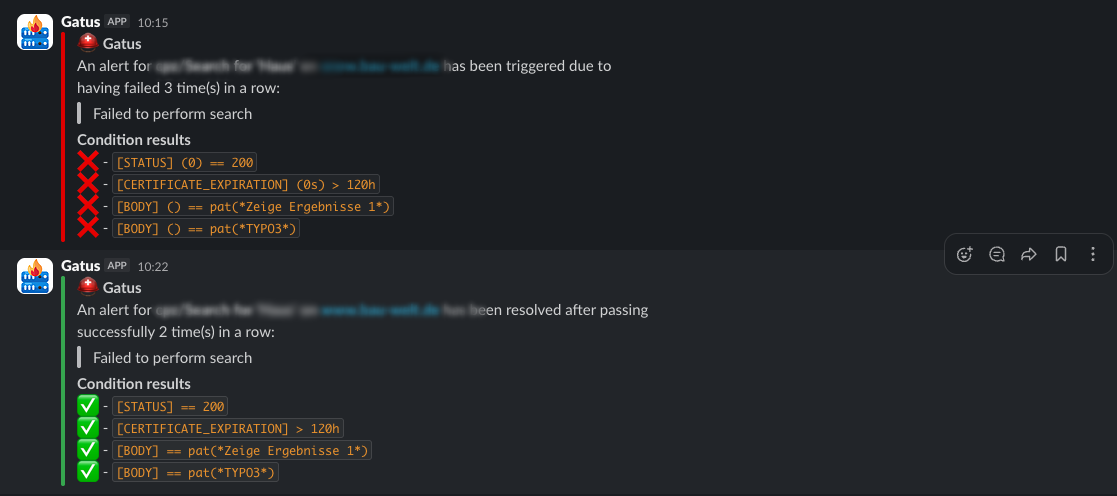
Aufgefallen ist uns das nicht durch einen Anruf, sondern durch Meldungen unseres Monitorings im Slack.
Wir setzen dafür Gatus ein und prüfen so automatisch zentrale Funktionen der Webseiten wie unter anderem die Suche. Das Monitoring läuft bewusst extern, also unabhängig von der Infrastruktur des Kunden.
So sehen wir auch Probleme, die intern eventuell gar nicht sofort auffallen.

Analyse: viele Requests, aber kein klarer Verursacher
Nach einem kurzen Check der Systeme haben wir uns die Logfiles des Produktivsystems angeschaut.
In einer zentralen Graylog-Instanz laufen alle Logs zusammen und können dort analysiert werden. In diesem Fall haben wir uns auf die Request-Logs aus Amazon CloudFront konzentriert. CloudFront kommt in diesem Fall als Content-Delivery-Network (CDN) zum Einsatz und alle Zugriffe auf die Site laufen dort durch.
Das erste Ergebnis war eindeutig:
Ein deutlicher Anstieg der ankommenden Requests auf die Webseite.
Normalerweise lässt sich die Ursache dann recht schnell eingrenzen, zum Beispiel über eine Häufung bestimmter IP-Adressen. In diesem Fall war das anders.
- keine auffällige Konzentration einzelner IPs
- dafür eine klare Häufung auf einer bestimmten URL
- und eine Häufung bei einem bestimmten User-Agent: eine einige Wochen alte Chrome-Version
Damit ergab sich ein deutlich klareres Bild.
Statt der üblichen 1 bis 2 Aufrufe pro Minute auf den Konfigurator lagen wir plötzlich bei fast 2.000 Requests pro Minute.
Zu viel für das System – insbesondere, weil die Antworten dynamisch erzeugt werden und nicht im Cache liegen.


Das eigentliche Muster: verteilt, aber koordiniert
Die weitere Analyse zeigte ein typisches Muster:
- pro IP-Adresse nur 3 bis 6 Requests
- danach Wechsel auf eine neue IP
- gleichbleibender User-Agent
Damit greifen klassische Schutzmechanismen wie Rate Limiting nicht mehr zuverlässig.
Und ebenso klar: Wer so vorgeht, hält sich in der Regel auch nicht an eine robots.txt. Diese versteht sich ohnehin technisch eher als “Vorschlag” an das anfragende System und stellt keine wirkliche Schutzmaßnahme gegen Anfragen dar.
Ob es sich um einen gezielten Angriff oder einfach um einen schlecht konfigurierten Bot handelt, lässt sich in solchen Fällen oft nicht eindeutig sagen. Für das System macht das allerdings keinen Unterschied.
Der eigentliche Unterschied: Kombinationen statt gezielte Nutzung
Was wir hier sehen, ist eine Verschiebung in der Nutzung. Es ging in diesem Fall nicht um eine klassische Suche. Betroffen war ein facettiertes Ergebnis. also eine Oberfläche, bei der sich Inhalte über verschiedene Filter und Parameter selektieren lassen.
Der Bot hat nicht gezielt Inhalte abgefragt, sondern ohne erkennbares Muster alle möglichen Kombinationen aufgerufen. Parameter an, Parameter aus, Werte variieren – und das in hoher Geschwindigkeit.
Für das System bedeutet das:
- jede Anfrage ist potenziell einzigartig
- kaum Wiederverwendung von Ergebnissen
- aufgrund der Vielzahl möglicher Ergebnisse praktisch keine sinnvolle Cachebarkeit
Während klassisches Crawling eher linear funktioniert, entsteht hier ein kombinatorischer Effekt. Und der skaliert schnell.
Was für einen Nutzer ein paar Klicks sind, werden für ein automatisiertes System tausende Varianten pro Minute.
Warum das kritisch ist
Solche Zugriffe wirken auf den ersten Blick absichtlich harmlos:
- gültige Requests
- realistische Parameter
- keine offensichtlichen Fehler
- wenige Anfragen durch den einzelnen Client
In der Summe erzeugen sie aber genau die Last, die Systeme an ihre Grenzen bringt. Nicht, weil einzelne Requests besonders teuer sind, sondern weil zu viele unterschiedliche Requests gleichzeitig sind.
Oder anders gesagt:
Das Problem ist nicht die einzelne Anfrage, sondern die Kombination aus Vielfalt und Geschwindigkeit.

Die Lösung: Challenge, damit das System für Menschen nutzbar bleibt
Ein klassisches Blocken war in diesem Fall keine sinnvolle Option, denn durch den ständigen Wechsel der IP-Adressen hätte man entweder zu spät reagiert oder das Risiko gehabt, legitime Nutzer mit auszuschließen.
Stattdessen haben wir die Maßnahmen dort angesetzt, wo sie greift: In der AWS WAF haben wir für den Konfigurator eine Challenge eingerichtet.
Das Prinzip dahinter: Echte Nutzer passieren unauffällig und automatisierte Zugriffe scheitern in der Regel. Damit konnten wir die Last gezielt reduzieren, ohne die Nutzung für echte Anwender einzuschränken.
Die Wirkung war unmittelbar sichtbar: Die Anzahl der Requests ging deutlich zurück und das System stabilisierte sich wieder.
Fazit
Die Last durch Bots und AI-Systeme und ihre speziellen Zugriffsmuster sind kein theoretisches Thema mehr. Sie sind im Alltag angekommen.
Es sind nicht mehr einzelne IP-Adressen, die viele Requests machen, sondern viele IPs machen jeweils wenige. Aber koordiniert.
Für das System fühlt sich das wie normale Nutzung an. In Summe ist es genau das Gegenteil.
Wir freuen uns, wenn Ihr diesen Beitrag teilt.
Kommentare
Julian
Vielen Dank für den Einblick. Klingt sehr spannend.
Vermissen tue ich etwas die technischen Details :-( Gibt's (oder folgt) dazu noch ein Blog-Post für Techies? Etwas mehr zu dem *was* in der WAF gemacht wurde?
Viele Grüße aus Würzburg
Julian
Ingo Schmitt
Hallo Julian,
wir haben als zusätzliche Regel beim AWS ein Challenge für den Pfad eingerichtet. Hier die Konfig als JSON
{
"Name": "ChallengeVisitors",
"Priority": 12,
"Statement": {
"ByteMatchStatement": {
"SearchString": "/$PFAD",
"FieldToMatch": {
"UriPath": {}
},
"TextTransformations": [
{
"Priority": 0,
"Type": "NONE"
}
],
"PositionalConstraint": "STARTS_WITH"
}
},
"VisibilityConfig": {
"SampledRequestsEnabled": true,
"CloudWatchMetricsEnabled": true,
"MetricName": "BlockBot"
},
"Action": {
"Challenge": {}
},
"CaptchaConfig": {
"ImmunityTimeProperty": {
"ImmunityTime": 300
}
}
}